
Amazon Redshift DC2インスタンスからRA3インスタンスへの移行戦略と実践
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。先日、Amazon Redshift 新しい最小インスタンス ra3.large インスタンスがリリースされました。本日は、新しい ra3.large インスタンスを用いて、DC2からRA3への移行戦略に基づき移行してみます。
RA3インスタンスとは
RA3 は「Redshift Architecture 3」の略で、 第3世代の Amazon Redshift アーキテクチャを表しています。RA3 インスタンスは、コンピューティングとストレージを分離した新しいアーキテクチャを採用することで、個別にスケーリングし、それぞれに対して別々に課金できます。
- Redshift Managed Storage(RMS) を使用し、ホットデータには高性能 SSD を、コールドデータには Amazon S3 を利用する
- 大規模なデータセットを処理するために最適化されており、従来のインスタンスタイプと比較して大容量のストレージを提供します
- RA3 は Nitro System 上に構築されており、専用ハードウェアとソフトウェアの組み合わせで、ベアメタルに近いパフォーマンスを実現している
- DC2の第2世代vCPUからRA3は第3世代vCPUを採用している
- データ共有、同時実行スケーリングの書き込み操作サポート、Zero-ETL、Multi AZ など、Redshift Managed Storage (RMS) のすべてのイノベーションを利用できる
このように、RA3 は Amazon Redshift の最新世代のアーキテクチャを表し、パフォーマンス、スケーラビリティ、コスト効率の向上を目的として設計されています。
DC2からRA3への移行戦略
前提
- エンドポイントの変更ができないため、RA3へ移行を前提とする
- 万が一の場合に迅速にロールバックできるようにBlue-Greenデプロイメントとし、現行インスタンスに変更を加える方式を採用しない
- スナップショットからリストアした後、クラスタをリサイズしてRA3インスタンスに移行する
- 新旧の切り替えは、エンドポイントの切り替え(CNAME Swap)
- 負荷の少ない曜日・時間帯に移行する
- 平日の午前9時に1時間と毎週月曜日の就業時間帯に負荷が高い
- 現在は、4つのdc2.largeで構成されたRedshiftクラスタを使用しています
移行方法
移行方法は、Elastic ResizeとClassic Resizeの2つあります。
- Elastic Resize
- 長所: データの配置(スライス)を変更せずにインスタンスのみを変更する方式で、リサイズの所要時間が短縮できる
- 短所: データスライスの不均等な分布によりノード間でデータに偏りが生じる可能性があり、処理負荷が水平分散できないため、Classic Resizeを使用する必要がある
- Classic Resize
- 長所: 変更するインスタンスやサイズに応じて再分散するため、ノード間でデータに偏りが生じないため、移行前のパフォーマンス傾向を維持できる
- 短所: データの配置(スライス)を変更するインスタンスやサイズに応じて再分散する方式で、リサイズの所要時間が増加する
現在は、RA3インスタンスへのClassic Resizeは、新しいクラスターへのデータ転送が最適化するこによって、リサイズ時間の短縮により、書き込みできない時間が減少しました。
よって、今回は、負荷の少ない時間帯に移行できるため、Classic Resizeを採用します。
クラスタのサイジング
サイジングとは、移行先のインスタンタイプやノード数を決めることです。サイジングのポイントは、CPUインテンシブ(CPUを多く使うクエリ)、I/Oインテンシブ(データの読み書きが多いクエリ)、その両方なのか等というワークロードの特性に応じてサイジングします。
クラスタのコストが同等もしくは下回るインスタンスサイズとインスタンス数で構成します。4つのdc2.largeに対して、推奨されるノード数は3つのra3.largeですが、今回はコストを優先して2つのra3.largeインスタンスに移行します。
- 推奨: 4つのdc2.large => 3つのra3.large
- $1.256/h (0.314/h * 4 nodes) => $1.917/h (0.639/h * 3 nodes)
- コスト重視: 4つのdc2.large => 2つのra3.large
- $1.256/h (0.314/h * 4 nodes) => $1.278/h (0.639/h * 2 nodes)
但し、上記のノード数では、時間帯によってスループット不足が懸念されます。その対策として、RA3インスタンスの同時実行スケーリングを有効にすることでスパイクアクセスに対処します。
なお、同時実行スケーリングはAWS アカウント内のアクティブなクラスターごとに 1 時間ごとに獲得され、クラスターごとに最大 30 時間の無料同時スケーリング クレジットを蓄積して利用します。この無料枠を超えた場合はオンデマンド利用費が発生します。
補足: Amzon Redshift のスケーリング戦略
今回は、同時実行スケーリングを採用しましたが、負荷の高い時間帯があらかじめわかっている場合はElastic Resizeを用いて一時的にノード数を増やしてパフォーマンスを増強する方式もあります。Elastic Resizeは、柔軟にパフォーマンスを増強できますが、増強した台数のオンデマンド利用費と切替時に短時間の切断が生じることから採用を見合わせます。
ストレージ料金
RA3インスタンスは、ストレージにS3(RMS: Redshift Managed Storage)を使用するため、データ量に応じてS3の料金が発生します。RA3インスタンスへ移行する際には、ストレージ料金もお見積りに含めてください。ただし、DC2の料金と比較するとストレージ料金は相対的に小さいため、今回は考慮しません。
パフォーマンス検証
DC2クラスタのスナップショットを取得し、Classic Resizeして検証用クラスタ(RA3クラスタ)を作成します。検証用クラスタでは、収集した代表的なクエリやピーク時のワークロードを検証用クラスタ(RA3クラスタ)で実行します。
- クエリ実行時間、CPU使用率、ディスクI/O、メモリ使用率などのメトリクスを比較します。
- CloudWatchを使用して詳細なメトリクス分析します。
- Explain Planを比較し、クエリの実行計画の変化を分析します。
パフォーマンスが足りない場合は、テーブルのチューニングやノード数の追加を検討します。
DC2からRA3への移行手順
現行DC2クラスタのスナップショットからRA3クラスタを作成した後、クラスター識別子を入れ替えます。詳細は、以下のとおりです。
1. 現行DC2クラスタのスナップショットを取得する
2. スナップショットから別のクラスター識別子のDC2クラスタをリストアする
3. 別のクラスター識別子のDC2クラスタをRA3インスタンスにClassic Resizeする
4. 現行DC2クラスタのクラスター識別子を変更する
5. RA3クラスタのクラスター識別子を元のクラスター識別子に変更する
執筆時点では、DC2の非暗号化スナップショットからRA3の暗号化(必須)へのリストアができないため、上記の手順になっていました。2025/6/13時点ではDC2のサポート終了に伴い、スナップショットから DC2 クラスターのリストアができなくなっておりました。現在は、DC2の非暗号化スナップショットからもRA3の暗号化のリストアがサポートされているため手順を以下のように変更します。
- 現行DC2クラスタのスナップショットを取得する
- スナップショットから別のクラスター識別子のRA3クラスタをリストアする
- 現行DC2クラスタのクラスター識別子を変更する
- RA3クラスタのクラスター識別子を元のクラスター識別子に変更する
もし、切り替えたあとに問題が生じたときには、切り戻し(元のDC2クラスタのクラスター識別子に戻す)素早く復旧できます。
DC2からRA3への移行
移行手順に従い、dc2.large の 4ノードのクラスタからdc2.large の 2ノードのクラスタをへの移行します。下記が現行のDC2クラスタです。
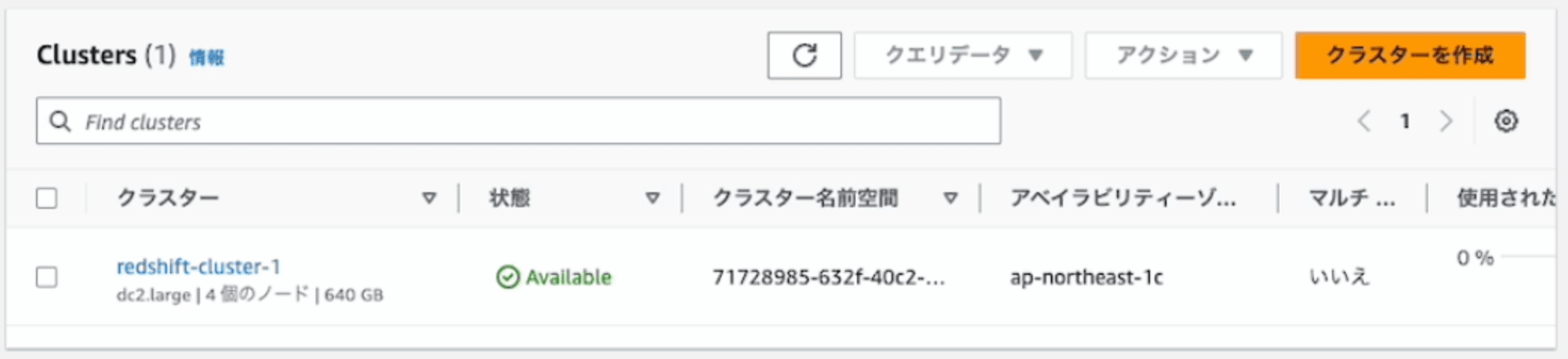
1. 現行DC2クラスタのスナップショットを取得する
現行DC2クラスタ(クラスター識別子redshift-cluster-1)のスナップショットを取得します。
なお、スナップショットは前回取得したスナップショットからの差分なので、事前にスナップショットを取得すると時間を短縮できます。
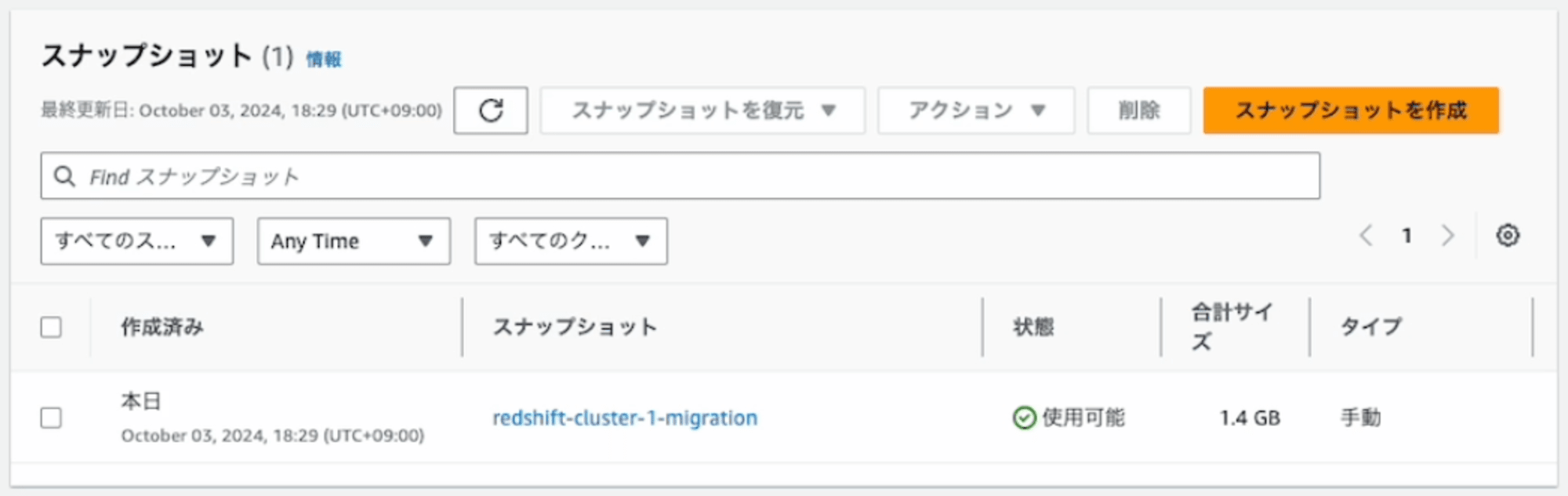
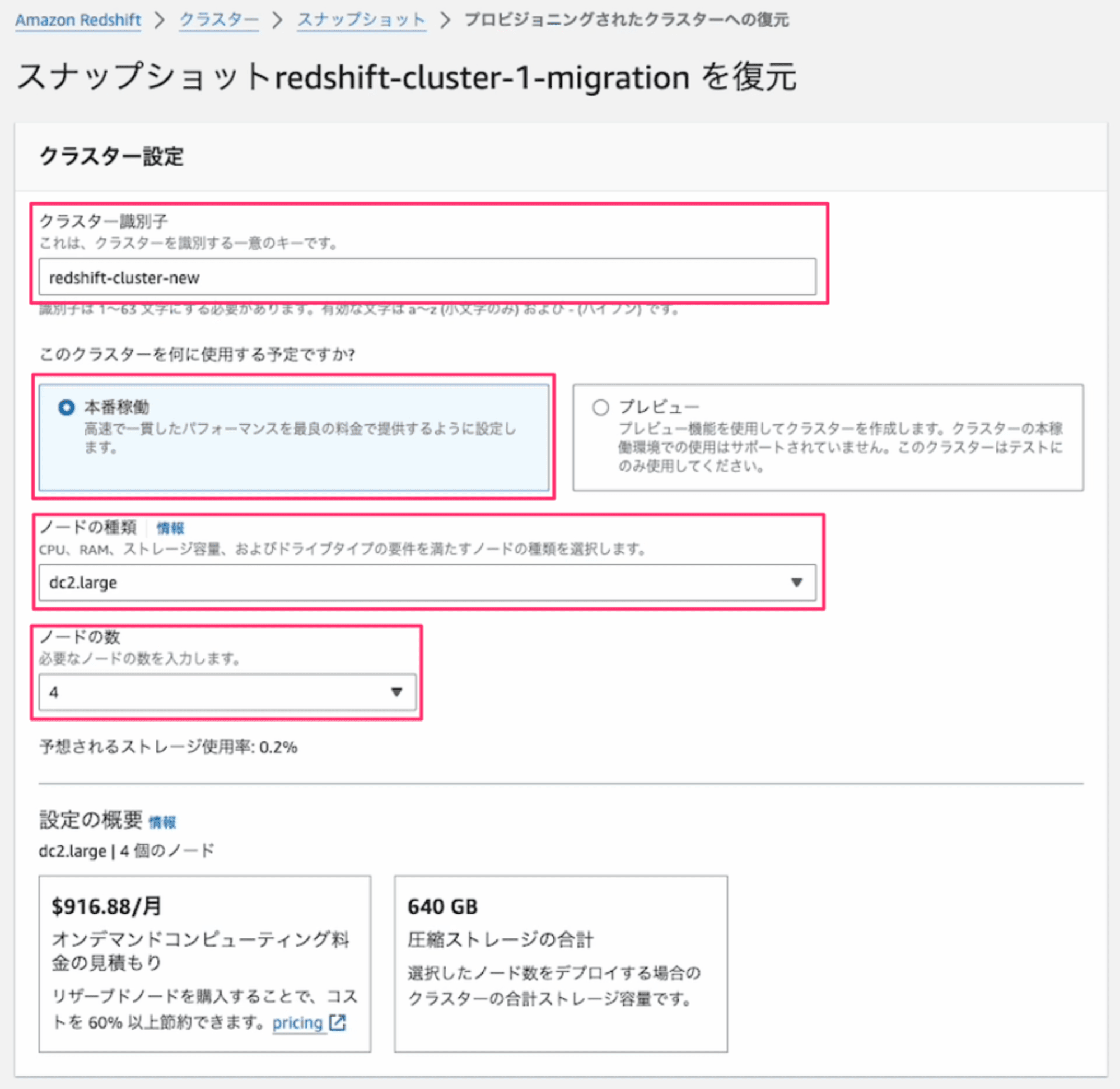
2. スナップショットから別のクラスター識別子のRA3クラスタをリストアする
現行DC2クラスタ(クラスター識別子redshift-cluster-1)のスナップショットからRA3クラスタ(クラスター識別子redshift-cluster-new)をリストアします。(下の画面キャプチャでは、「ノードの種類」がdc2インスタンスになっていますが、ra3インスタンスに読み替えてください。)
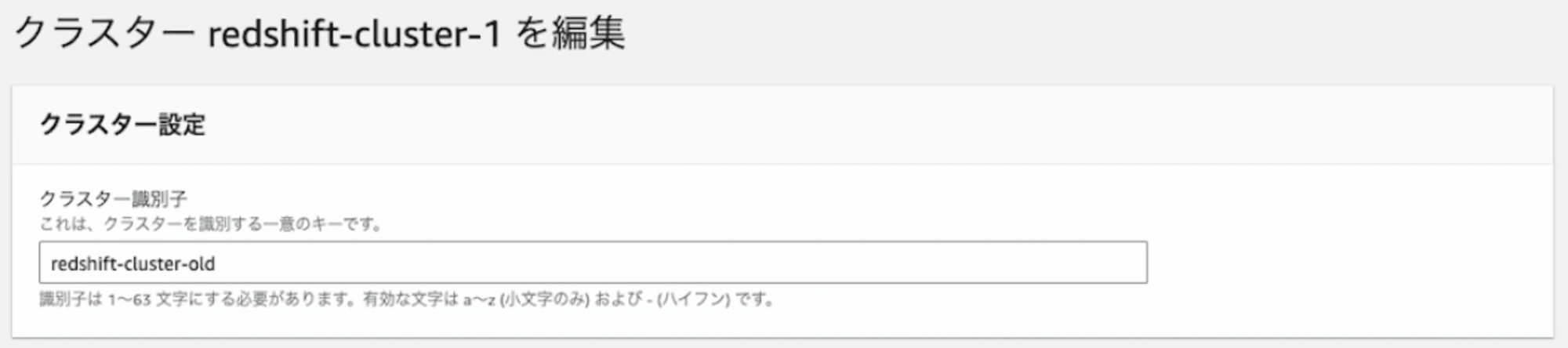
3. 現行DC2クラスタのクラスター識別子を変更する
現行DC2クラスタと移行後のRA3クラスタのクラスター識別子が重複しないように、今回は現行DC2クラスタのクラスター識別子をredshift-cluster-1からredshift-cluster-oldに変更します。
4. RA3クラスタのクラスター識別子を元のクラスター識別子に変更する
移行後のRA3クラスタのクラスター識別子をredshift-cluster-newからredshift-cluster-1に変更します。これで移行後のエンドポイントが変更されずに済むため、Redshiftに接続するアプリケーションやBIツールの変更は不要になります。
移行の所要時間(目安)
今回の検証に用いたクラスタはデータ量が少なかったため、移行の所要時間が短くなりました。手順2のリストアと手順3のClassic Resizeは、データ量や移行先のクラスタのスペックによって所要時間が大きく変動します。そのため、これら工程については事前にリハーサルを実施して所要時間を計測することをお勧めします。
| 手順 | 内容 | 所要時間(目安) |
|---|---|---|
| 1 | 現行DC2クラスタのスナップショットを取得する | 1.5分 |
| 2 | スナップショットから別のクラスター識別子のRA3クラスタをリストアする | 7分 |
| 3 | 現行DC2クラスタのクラスター識別子を変更する | 4分 |
| 4 | RA3クラスタのクラスター識別子を元のクラスター識別子に変更する | 5.5分 |
| 合計 | 18分 |
最後に
新しいra3.largeインスタンスがリリースされたのを機に、最新の情報に基づいて移行戦略を見直し、実際に移行しました。予想通り、実施してみると想定と異なる点がいくつかあり、検証した価値がありました。今回は移行に十分な時間を取れる前提で計画を立てました。
ワークロードによりますが、RA3インスタンスでは、最新のNitroインスタンスや第3世代vCPUによるベースラインパフォーマンスの改善が見込めます。さらに、自動マテリアライズドビュー(AutoMV)のように安価なストレージを活用してパフォーマンスを改善する仕組みも利用できるようになります。DC2インスタンスからRA3インスタンスへのマイグレーションを行うことで、Redshiftの最新機能が利用可能になり、ストレージの制限も大幅に緩和されます。これらの利点を踏まえると、RA3インスタンスへの移行を検討することをお勧めします。










